Generative AI is cool, but let’s not forget its human and environmental costs.

Over the past few months, the field of artificial intelligence has seen rapid growth, with wave after wave of new models such as Dall-E and GPT-4 appearing one after another. Exciting new models, products and tools are promised every week. It’s easy to get carried away by waves of hype, but these brilliant opportunities come at a cost to society and the planet.
Drawbacks include the environmental cost of mining rare minerals, the human cost of the time-consuming data annotation process, and the growing financial investment required to train AI models as they include more parameters.
Let’s take a look at the innovations that have led to the latest generations of these models and have driven up the costs associated with them.
Large Models
AI models have gotten bigger in recent years, with researchers now measuring their size in hundreds of billions of parameters. “Parameters”are internal relationships used in models to learn patterns based on training data.
For large language models (LLMs) like ChatGPT, we’ve increased the number of parameters from 100 million in 2018 to 500 billion in 2023 thanks to Google’s PaLM model. The theory behind this growth is that models with more parameters should have better performance even on tasks they were not originally trained on, although this hypothesis remains unproven.
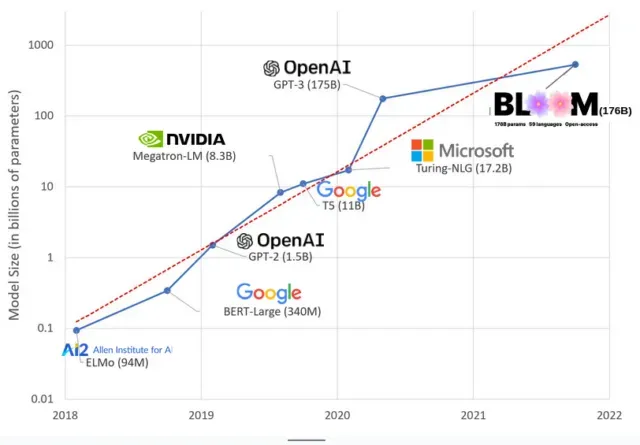
Large models usually take longer to train, which means they also require more GPUs, which cost more money, so only a select few organizations can train them. The cost of training GPT-3, which has 175 billion parameters, is estimated at $4.6 million, which is out of reach for most companies and organizations. (It is worth noting that the cost of training models is reduced in some cases, such as in the case of LLaMA, a recent model trained by Meta.)
This is creating a digital divide in the AI community between those who can teach the most cutting-edge LLMs (mostly big tech companies and wealthy institutions in the Global North) and those who can’t (non-profits, start-ups, and anyone who doesn’t have access to a supercomputer). or millions in cloud credits). Building and deploying these giants requires a lot of planetary resources: rare metals to manufacture GPUs, water to cool huge data centers, energy to keep those data centers running 24/7 on a planetary scale… all of which are often overlooked in favor of focusing attention. about the future potential of the resulting models.
planetary influences
A study by Carnegie Mellon University professor Emma Strubell on the carbon footprint of LLM training found that training a 2019 model called BERT, which has only 213 million parameters, emits 280 metric tons of carbon emissions, roughly the equivalent of five cars. life. Since then, models have grown and equipment has become more efficient, so where are we now?
In a recent scientific paper I wrote to study the carbon emissions caused by training BLOOM, a language model with 176 billion parameters, we compared the energy consumption and subsequent carbon emissions of several LLMs, all of which have come out in the last few years. The purpose of the comparison was to get an idea of the scale of LLM emissions of different sizes and what influences them.
Leave a Reply