Generativ AI er cool, men lad os ikke glemme dens menneskelige og miljømæssige omkostninger.

I løbet af de sidste par måneder har feltet for kunstig intelligens oplevet hastig vækst, hvor bølge efter bølge af nye modeller som Dall-E og GPT-4 dukker op efter hinanden. Spændende nye modeller, produkter og værktøjer loves hver uge. Det er nemt at lade sig rive med af bølger af hype, men disse geniale muligheder koster samfundet og planeten.
Ulemperne omfatter de miljømæssige omkostninger ved udvinding af sjældne mineraler, de menneskelige omkostninger ved den tidskrævende dataannoteringsproces og den voksende økonomiske investering, der kræves for at træne AI-modeller, da de inkluderer flere parametre.
Lad os tage et kig på de innovationer, der har ført til de seneste generationer af disse modeller og har drevet omkostningerne forbundet med dem op.
Store modeller
AI-modeller er blevet større i de senere år, hvor forskere nu måler deres størrelse i hundredvis af milliarder af parametre. “Parametre” er interne relationer, der bruges i modeller til at lære mønstre baseret på træningsdata.
For store sprogmodeller (LLM’er) som ChatGPT har vi øget antallet af parametre fra 100 millioner i 2018 til 500 milliarder i 2023 takket være Googles PaLM-model. Teorien bag denne vækst er, at modeller med flere parametre bør have bedre ydeevne selv på opgaver, de ikke oprindeligt blev trænet i, selvom denne hypotese forbliver ubevist .
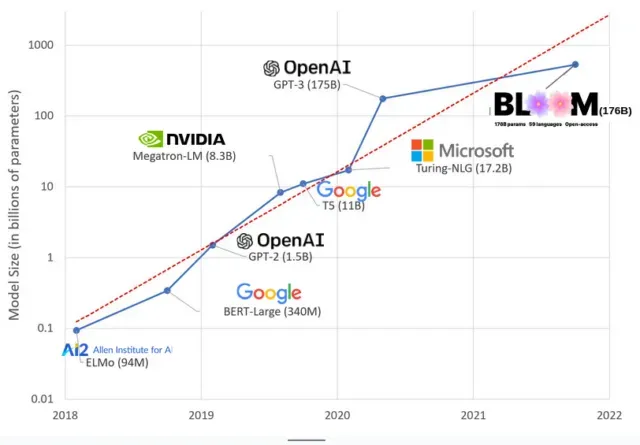
Store modeller tager normalt længere tid at træne, hvilket betyder, at de også kræver flere GPU’er, hvilket koster flere penge, så kun nogle få udvalgte organisationer kan træne dem. Omkostningerne ved at træne GPT-3, som har 175 milliarder parametre, er anslået til 4,6 millioner dollars, hvilket er uden for rækkevidde for de fleste virksomheder og organisationer. (Det er værd at bemærke, at omkostningerne ved træningsmodeller reduceres i nogle tilfælde , f.eks. i tilfældet med LLaMA, en nyere model trænet af Meta.)
Dette skaber en digital kløft i AI-fællesskabet mellem dem, der kan undervise de mest banebrydende LLM’er (for det meste store teknologivirksomheder og velhavende institutioner i det globale nord) og dem, der ikke kan (non-profit, start-ups) , og alle, der ikke har adgang til en supercomputer). eller millioner i cloud-kreditter). Opbygning og udrulning af disse giganter kræver mange planetariske ressourcer: sjældne metaller til fremstilling af GPU’er, vand til at afkøle enorme datacentre, energi til at holde disse datacentre kørende 24/7 på planetarisk skala … som alt sammen ofte overses til fordel for fokusering opmærksomhed. om det fremtidige potentiale for de resulterende modeller.
planetariske påvirkninger
En undersøgelse af Carnegie Mellon University-professor Emma Strubell om CO2-fodaftrykket af LLM-træning viste, at træning af en 2019-model kaldet BERT, som kun har 213 millioner parametre, udleder 280 tons kulstofemission, hvilket omtrent svarer til fem biler. liv. Siden da er modellerne vokset, og udstyret er blevet mere effektivt, så hvor er vi nu?
I en nylig videnskabelig artikel, jeg skrev for at studere kulstofemissioner forårsaget af træning BLOOM, en sprogmodel med 176 milliarder parametre, sammenlignede vi energiforbruget og efterfølgende kulstofemissioner fra flere LLM’er, som alle er kommet ud i de sidste par år. Formålet med sammenligningen var at få en idé om omfanget af LLM-emissioner af forskellige størrelser, og hvad der påvirker dem.
Skriv et svar