La IA generativa es genial, pero no olvidemos sus costos humanos y ambientales.

En los últimos meses, el campo de la inteligencia artificial ha experimentado un rápido crecimiento, con ola tras ola de nuevos modelos, como Dall-E y GPT-4, que aparecen uno tras otro. Cada semana se prometen nuevos y emocionantes modelos, productos y herramientas. Es fácil dejarse llevar por las oleadas de publicidad, pero estas brillantes oportunidades tienen un costo para la sociedad y el planeta.
Los inconvenientes incluyen el costo ambiental de extraer minerales raros, el costo humano del proceso de anotación de datos que requiere mucho tiempo y la creciente inversión financiera requerida para entrenar modelos de IA a medida que incluyen más parámetros.
Echemos un vistazo a las innovaciones que han dado lugar a las últimas generaciones de estos modelos y han aumentado los costos asociados con ellos.
modelos grandes
Los modelos de IA se han vuelto más grandes en los últimos años, y los investigadores ahora miden su tamaño en cientos de miles de millones de parámetros. Los «parámetros» son relaciones internas utilizadas en modelos para aprender patrones basados en datos de entrenamiento.
Para modelos de lenguaje extenso (LLM) como ChatGPT, hemos aumentado la cantidad de parámetros de 100 millones en 2018 a 500 mil millones en 2023 gracias al modelo PaLM de Google. La teoría detrás de este crecimiento es que los modelos con más parámetros deberían tener un mejor rendimiento incluso en tareas en las que no fueron entrenados originalmente, aunque esta hipótesis sigue sin probarse .
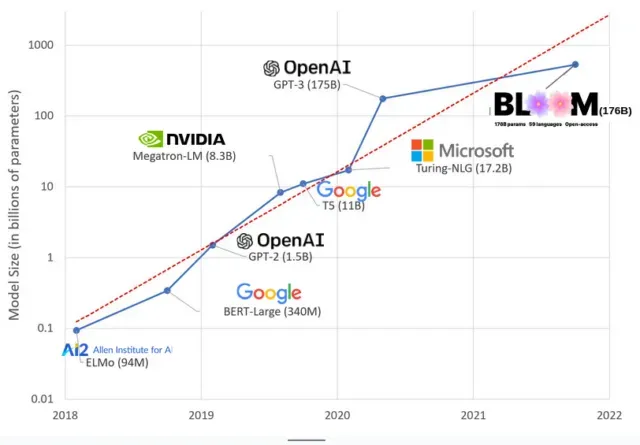
Los modelos grandes suelen tardar más en entrenarse, lo que significa que también requieren más GPU, lo que cuesta más dinero, por lo que solo unas pocas organizaciones pueden entrenarlos. El costo de entrenar GPT-3, que tiene 175 mil millones de parámetros, se estima en $4.6 millones, lo que está fuera del alcance de la mayoría de las empresas y organizaciones. (Cabe señalar que el costo de los modelos de entrenamiento se reduce en algunos casos , como en el caso de LLaMA, un modelo reciente entrenado por Meta).
Esto está creando una brecha digital en la comunidad de IA entre aquellos que pueden enseñar los LLM más avanzados (principalmente grandes empresas tecnológicas e instituciones ricas en el Norte Global) y aquellos que no pueden (organizaciones sin fines de lucro, empresas emergentes). , y cualquiera que no tenga acceso a una supercomputadora). o millones en créditos de nube). Construir y desplegar estos gigantes requiere una gran cantidad de recursos planetarios: metales raros para fabricar GPU, agua para enfriar enormes centros de datos, energía para mantener esos centros de datos funcionando las 24 horas del día, los 7 días de la semana a escala planetaria… todo lo cual a menudo se pasa por alto a favor de enfocarse atención. sobre el potencial futuro de los modelos resultantes.
influencias planetarias
Un estudio realizado por la profesora de la Universidad Carnegie Mellon, Emma Strubell, sobre la huella de carbono del entrenamiento LLM encontró que entrenar un modelo 2019 llamado BERT, que tiene solo 213 millones de parámetros, emite 280 toneladas métricas de emisiones de carbono, aproximadamente el equivalente de cinco autos. vida. Desde entonces, los modelos han crecido y los equipos se han vuelto más eficientes, entonces, ¿dónde estamos ahora?
En un artículo científico reciente que escribí para estudiar las emisiones de carbono causadas por el entrenamiento de BLOOM, un modelo de lenguaje con 176 mil millones de parámetros, comparamos el consumo de energía y las emisiones de carbono posteriores de varios LLM, todos los cuales han aparecido en los últimos años. El propósito de la comparación fue tener una idea de la escala de las emisiones LLM de diferentes tamaños y qué las influye.
Deja una respuesta