Generatieve AI is cool, maar laten we de menselijke en ecologische kosten niet vergeten.

De afgelopen maanden heeft het gebied van kunstmatige intelligentie een snelle groei doorgemaakt, met golf na golf van nieuwe modellen zoals Dall-E en GPT-4 die na elkaar verschenen. Elke week worden er spannende nieuwe modellen, producten en gereedschappen beloofd. Het is gemakkelijk om meegesleept te worden door golven van hype, maar deze briljante kansen brengen kosten met zich mee voor de samenleving en de planeet.
Nadelen zijn onder meer de milieukosten van het ontginnen van zeldzame mineralen, de menselijke kosten van het tijdrovende data-annotatieproces en de groeiende financiële investering die nodig is om AI-modellen te trainen omdat ze meer parameters bevatten.
Laten we eens kijken naar de innovaties die hebben geleid tot de nieuwste generaties van deze modellen en die de bijbehorende kosten hebben opgedreven.
Grote modellen
AI-modellen zijn de afgelopen jaren groter geworden en onderzoekers meten nu hun omvang in honderden miljarden parameters. “Parameters” zijn interne relaties die in modellen worden gebruikt om patronen te leren op basis van trainingsgegevens.
Voor grote taalmodellen (LLM’s) zoals ChatGPT hebben we het aantal parameters verhoogd van 100 miljoen in 2018 tot 500 miljard in 2023 dankzij het PaLM-model van Google. De theorie achter deze groei is dat modellen met meer parameters betere prestaties zouden moeten leveren, zelfs bij taken waarvoor ze oorspronkelijk niet waren getraind, hoewel deze hypothese onbewezen blijft .
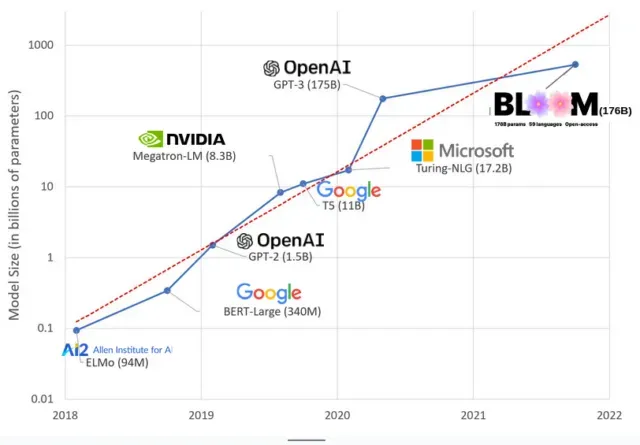
Grote modellen hebben meestal meer tijd nodig om te trainen, wat betekent dat ze ook meer GPU’s nodig hebben, wat meer geld kost, dus slechts een beperkt aantal organisaties kunnen ze trainen. De kosten van het trainen van GPT-3, dat 175 miljard parameters heeft, worden geschat op 4,6 miljoen dollar, wat voor de meeste bedrijven en organisaties onbereikbaar is. (Het is vermeldenswaard dat de kosten van het trainen van modellen in sommige gevallen worden verlaagd , zoals in het geval van LLaMA, een recent model dat door Meta is getraind.)
Dit creëert een digitale kloof in de AI-gemeenschap tussen degenen die de meest geavanceerde LLM’s kunnen onderwijzen (meestal grote technologiebedrijven en rijke instellingen in het mondiale noorden) en degenen die dat niet kunnen (non-profitorganisaties, start-ups , en iedereen die geen toegang heeft tot een supercomputer). of miljoenen aan cloudcredits). Het bouwen en inzetten van deze reuzen vereist veel planetaire hulpbronnen: zeldzame metalen om GPU’s te maken, water om enorme datacenters te koelen, energie om die datacenters 24/7 draaiende te houden op planetaire schaal… die allemaal vaak over het hoofd worden gezien ten gunste van focus aandacht. over het toekomstige potentieel van de resulterende modellen.
planetaire invloeden
Uit een onderzoek van Emma Strubell , professor aan de Carnegie Mellon University, naar de CO2-voetafdruk van LLM-training bleek dat het trainen van een model uit 2019, BERT genaamd, dat slechts 213 miljoen parameters heeft, 280 ton CO2-uitstoot veroorzaakt, ongeveer het equivalent van vijf auto’s. leven. Sindsdien zijn modellen gegroeid en is apparatuur efficiënter geworden, dus waar staan we nu?
In een recent wetenschappelijk artikel dat ik schreef om de koolstofemissies te bestuderen die worden veroorzaakt door het trainen van BLOOM, een taalmodel met 176 miljard parameters, vergeleken we het energieverbruik en de daaropvolgende koolstofemissies van verschillende LLM’s, die allemaal de afgelopen jaren zijn verschenen. Het doel van de vergelijking was om een idee te krijgen van de omvang van LLM-emissies van verschillende groottes en wat daarop van invloed is.
Geef een reactie