Generativ AI är coolt, men låt oss inte glömma dess mänskliga och miljömässiga kostnader.

Under de senaste månaderna har området för artificiell intelligens sett en snabb tillväxt, med våg efter våg av nya modeller som Dall-E och GPT-4 som dykt upp en efter en. Spännande nya modeller, produkter och verktyg utlovas varje vecka. Det är lätt att ryckas med av vågor av hype, men dessa lysande möjligheter kostar samhället och planeten.
Nackdelarna inkluderar miljökostnaden för att bryta sällsynta mineraler, den mänskliga kostnaden för den tidskrävande dataanteckningsprocessen och den växande ekonomiska investeringen som krävs för att träna AI-modeller eftersom de inkluderar fler parametrar.
Låt oss ta en titt på de innovationer som har lett till de senaste generationerna av dessa modeller och har drivit upp kostnaderna förknippade med dem.
Stora modeller
AI-modeller har blivit större de senaste åren, med forskare som nu mäter deras storlek i hundratals miljarder parametrar. ”Parametrar” är interna relationer som används i modeller för att lära sig mönster baserat på träningsdata.
För stora språkmodeller (LLM) som ChatGPT har vi ökat antalet parametrar från 100 miljoner 2018 till 500 miljarder 2023 tack vare Googles PaLM-modell. Teorin bakom denna tillväxt är att modeller med fler parametrar bör ha bättre prestanda även på uppgifter som de inte ursprungligen tränades på, även om denna hypotes fortfarande är obevisad .
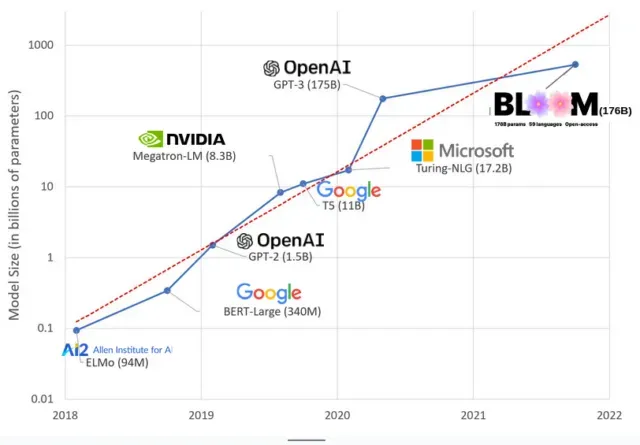
Stora modeller tar vanligtvis längre tid att träna, vilket innebär att de också kräver fler GPU:er, vilket kostar mer pengar, så endast ett fåtal utvalda organisationer kan träna dem. Kostnaden för att träna GPT-3, som har 175 miljarder parametrar, uppskattas till 4,6 miljoner dollar, vilket är utom räckhåll för de flesta företag och organisationer. (Det är värt att notera att kostnaden för träningsmodeller minskar i vissa fall , till exempel i fallet med LLaMA, en ny modell utbildad av Meta.)
Detta skapar en digital klyfta i AI-gemenskapen mellan de som kan lära ut de mest banbrytande LLM:erna (främst stora teknikföretag och rika institutioner i den globala norra) och de som inte kan (icke-vinstdrivande, nystartade företag) , och alla som inte har tillgång till en superdator). eller miljoner i molnkrediter). Att bygga och distribuera dessa jättar kräver många planetära resurser: sällsynta metaller för att tillverka GPU:er, vatten för att kyla enorma datacenter, energi för att hålla dessa datacenter igång 24/7 på en planetarisk skala… allt detta förbises ofta till förmån för fokusering uppmärksamhet. om den framtida potentialen för de resulterande modellerna.
planetariska influenser
En studie av Carnegie Mellon University-professorn Emma Strubell om koldioxidavtrycket för LLM-utbildning fann att träning av en 2019-modell kallad BERT, som bara har 213 miljoner parametrar, släpper ut 280 ton koldioxidutsläpp, ungefär motsvarande fem bilar. liv. Sedan dess har modellerna vuxit och utrustningen har blivit effektivare, så var är vi nu?
I en nyligen publicerad vetenskaplig artikel jag skrev för att studera koldioxidutsläppen orsakade av träning BLOOM, en språkmodell med 176 miljarder parametrar, jämförde vi energiförbrukningen och efterföljande koldioxidutsläpp för flera LLM, som alla har kommit ut under de senaste åren. Syftet med jämförelsen var att få en uppfattning om omfattningen av LLM-utsläpp av olika storlekar och vad som påverkar dem.
Lämna ett svar